Reklame
 Når det kommer til online databaser og information, der kan findes i det, der almindeligvis kaldes "usynlig web De 12 bedste søgemaskiner til at udforske det usynlige webGoogle eller Bing kan ikke søge efter alt. For at udforske det usynlige web skal du bruge disse specielle søgemaskiner. Læs mere ”, Jeg er ikke din typiske bruger. Jada, jeg bruger lidt for meget af min tid på at søge gennem online databaser på steder som Nationalarkivet og CIA FOIA læsning værelse, men jeg må ikke sige, at intet gør mig mere begejstret, end når jeg finder en HTML-baseret tabel fyldt med mængder af tilsyneladende kompleks og uden forbindelse data.
Når det kommer til online databaser og information, der kan findes i det, der almindeligvis kaldes "usynlig web De 12 bedste søgemaskiner til at udforske det usynlige webGoogle eller Bing kan ikke søge efter alt. For at udforske det usynlige web skal du bruge disse specielle søgemaskiner. Læs mere ”, Jeg er ikke din typiske bruger. Jada, jeg bruger lidt for meget af min tid på at søge gennem online databaser på steder som Nationalarkivet og CIA FOIA læsning værelse, men jeg må ikke sige, at intet gør mig mere begejstret, end når jeg finder en HTML-baseret tabel fyldt med mængder af tilsyneladende kompleks og uden forbindelse data.
Faktum er, datatabeller er en guldgruve af vigtige sandheder. Data indsamles ofte af hære af dataindsamling grynt med støvler på jorden. Du har folk fra den amerikanske folketælling, der rejser rundt i hele landet for information om husholdning og familie. Du har ikke-kommercielle miljøgrupper, der samler alle mulige interessante oplysninger om miljøet, forurening, global opvarmning og mere. Og hvis du går ind i den paranormale eller Ufology, er der også konstant opdaterede tabeller med information om observationer af mærkelige genstande på himlen over os.
Ironisk nok ville du tro, at enhver regering i verden ville være interesseret i at vide, hvilken slags udenlandske fartøjer bliver set på himlen over ethvert land, men tilsyneladende ikke - i det mindste ikke i U.S. alligevel. I Amerika er samlingen af usædvanlige observationer af kunsthåndværk blevet henvist til hold af amatørhobbyister, der strømmer til nye UFO-observationer som møll til en flamme. Min interesse for disse observationer stammer faktisk ikke fra en fascination af udlændinge eller håndværk fra andre planeter, men fra en videnskabelig fascination af mønstre - hvor og hvorfor flere mennesker ser ting på himlen, og om disse observationer kunne afspejle noget meget reelt og meget mere jordnært på.
For at udforske mængderne af data indsamlet af teams af UFO-hobbyister har jeg faktisk udviklet en måde at importere store HTML-tabeller på data i et Google-regneark, og derefter manipulere og analysere disse data for at udtrække og opdage meningsfulde og vigtige Information. I denne artikel har jeg til hensigt at vise dig, hvordan du gør det samme.
Vigtige HTML-data i Google-regnearket
I dette eksempel vil jeg vise dig, hvordan du importerer data, der muligvis kan gemmes i en tabel på ethvert websted på Internettet, til dit Google Regneark. Tænk på den enorme mængde data, der er tilgængelig på Internettet i dag i form af HTML-tabeller. Wikipedia alene har data i tabeller for emner som global opvarmning, har det amerikanske folketællingsbureau masser af populationsdatasæt, og en lille smule Googling vil lande dig meget mere ud over det.
I mit eksempel starter jeg med en database på National UFO Reporting Center, der rent faktisk ser ud som om det kan være en forespørgsel-stil-web-database, men hvis du observerer URL-strukturering, det er faktisk et semikompleks webbaseret rapporteringssystem, der består af statiske websider og statiske HTML-tabeller - nøjagtigt hvad vi ønsker, når vi leder efter data til importere.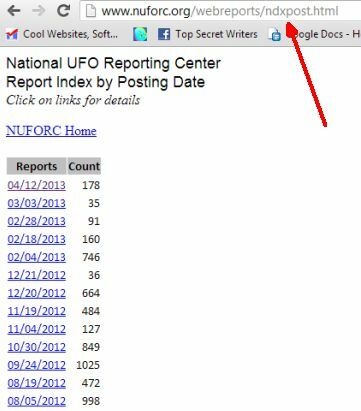
NUForc.org er en af de organisationer, der fungerer som et af de største rapporteringscentre for UFO-observationer. Det er ikke den eneste, men det er stort nok til at finde nye datasæt med aktuelle observationer for hver måned. Du vælger at se de data, der er sorteret efter kriterier som stat eller dato, og hver af disse leveres i form af en statisk side. Hvis du sorterer efter dato og derefter klikker på den seneste dato, vil du se, at tabellen der er anført der er en statisk webside, der er navngivet i henhold til datoformatet.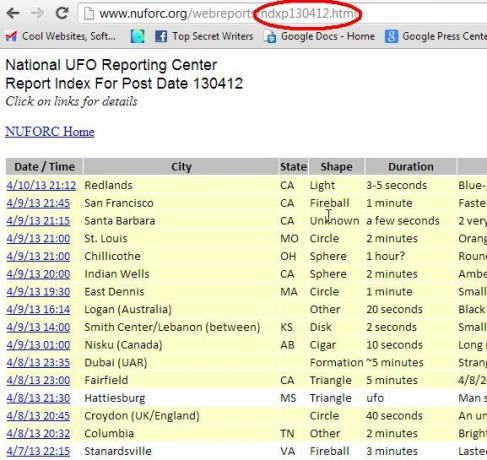
Så vi har nu et mønster til regelmæssigt at udtrække de nyeste observationsoplysninger fra denne HTML-baserede database. Alt hvad du skal gøre er at importere den første tabel og bruge den seneste post (den øverste) til at identificere den seneste opdatering, og brug derefter datoen for denne bogføring til at oprette URL-linket, hvor den nyeste HTML-datatabel er eksisterer. Dette kræver simpelthen et par tilfælde af ImportHTML-funktionen og derefter et par kreative anvendelser af tekstmanipulationsfunktioner. Når du er færdig, har du et af de fedeste, selvopdaterende rapporteringsspreadsheets af dit helt eget. Lad os komme igang.
Import af tabeller og manipulation af data
Det første trin er selvfølgelig at oprette det nye regneark.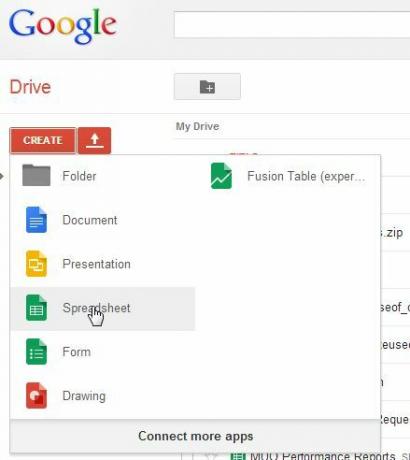
Så hvordan importerer du HTML-tabeller? Alt hvad du behøver er den URL, hvor tabellen er gemt, og nummeret på tabellen på siden - normalt er den første, der er opført på 1, den anden er 2, og så videre. Da jeg kender URL'en til den første tabel, der viser datoer og tællinger af de anførte observationer, er det muligt at importere ved at indtaste følgende funktion i celle A1.
= Importhtml ( ” http://www.nuforc.org/webreports/ndxpost.html?”&H2,”table”,1)
H2 har funktionen “= time (nu ())“, Så tabellen opdateres hver time. Dette er sandsynligvis ekstremt for data, der opdaterer dette sjældent, så jeg kunne sandsynligvis slippe af sted med at gøre det dagligt. Under alle omstændigheder bringer ovenstående ImportHTML-funktion tabellen som vist nedenfor.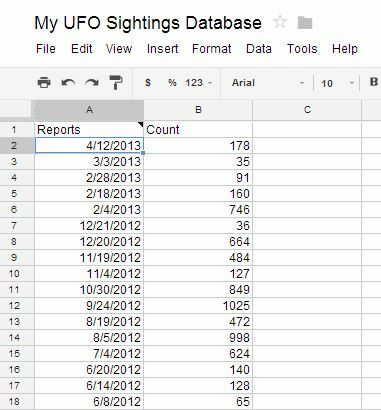
Du skal foretage en smule datamanipulation på denne side, før du kan dele URL'en til den anden tabel sammen med alle UFO-observationer. Men fortsæt med at oprette det andet ark i projektmappen.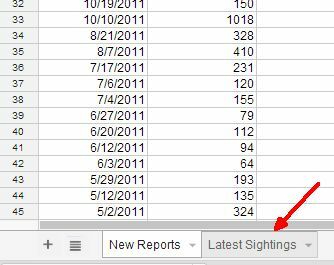
Før du prøver at bygge det andet ark, er det tid til at udtrække postdatoen fra denne første tabel for at oprette linket til den anden tabel. Problemet er, at datoen indføres som et datoformat, ikke som en streng. Så skal du først bruge TEXT-funktionen til at konvertere rapportpostdatoen til en streng:
= tekst (A2, ”mm / dd / åååå”)
I den næste celle til højre skal du bruge SPLIT-funktionen med "/" -afgrænseren til at opdele datoen i måned, dag og år.
= split (D2, ”/”)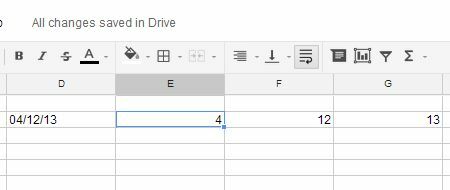
Ser godt ud! Dog skal hvert nummer tvinges til to cifre. Dette gør du i cellerne lige under dem ved hjælp af kommandoen TEXT igen.
= tekst (E2, ”00 ″)
Et format på "00" (det er nuller) tvinger to cifre eller et "0" som en pladsholder.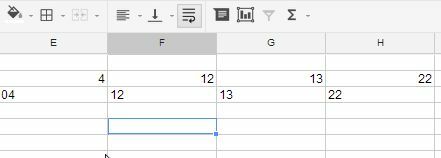
Nu er du klar til at genopbygge hele URL'en til den nyeste HTML-tabel med nye observationer. Du kan gøre dette ved at bruge CONCATENATE-funktionen og samle alle de informationsbits, du lige har uddraget fra den første tabel.
= CONCATENATE ( ” http://www.nuforc.org/webreports/ndxp”,G3,E3,F3,”.html”)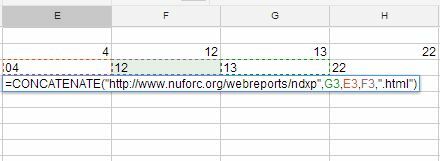
Nu på det nye ark, du oprettede ovenfor (det blanke ark), skal du udføre en ny “importhtml” -funktion, men denne gang for den første URL-linkparameter, så du vil navigere tilbage til det første regneark og klikke på cellen med det URL-link, du lige har oprettet.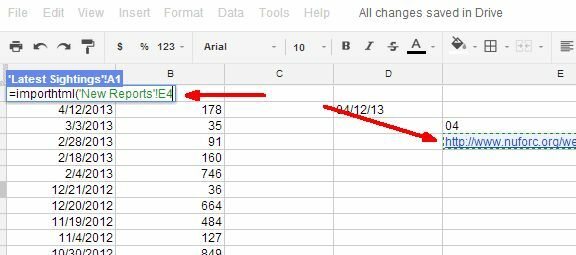
Den anden parameter er "tabel" og den sidste er "1" (fordi synstabellen er den første og eneste på siden). Tryk på Enter, og nu har du lige importeret hele mængden af observationer, der blev lagt ud på den bestemte dato.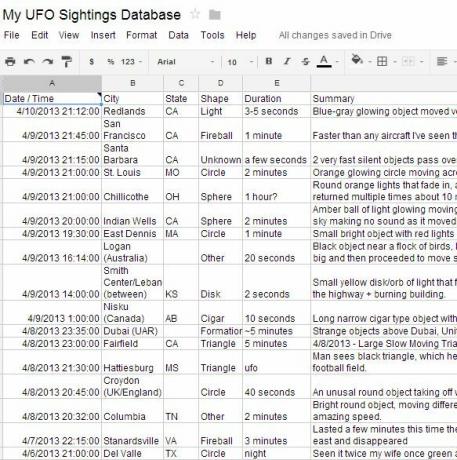
Så tænker du sandsynligvis, at dette er en dejlig nyskabelse, og alting - jeg mener, når alt kommer til alt, hvad du har gjort eksisterende oplysninger fra en tabel på Internettet og migreret den til en anden tabel, omend en privat i dine Google Dokumenter konto. Ja det er sandt. Men nu det er på din egen private Google Docs-konto, har du lige ved hånden værktøjer og funktioner til bedre at analysere disse data og begynde at opdage fantastiske forbindelser.
Brug af Pivot-rapporter til analyse af importerede data
For nylig skrev jeg en artikel om brug Drej rapporter i Google Regneark Bliv ekspertdataanalytiker natten over ved hjælp af Googles regnearkrapportværktøjerVidste du, at et af de største værktøjer af alle til at udføre dataanalyse faktisk er Google Spreadsheet? Årsagen til dette er ikke kun fordi det kan gøre næsten alt hvad du måske vil ... Læs mere at udføre alle mulige cool dataanalysefeat. Du kan godt udføre den samme fantastiske akrobatik til dataanalyse på de data, du har importeret fra Internettet - giver dig mulighed for at afdække interessante forbindelser, som muligvis ingen andre har afsløret før du.
For eksempel fra den endelige observationstabel kan jeg måske beslutte at bruge en pivotrapport til at se på antallet af forskellige unikke former rapporteret i hver tilstand sammenlignet med det samlede antal observationer i den pågældende bestemt stat. Endelig filtrerer jeg også alt, der nævner “aliens” i kommentarfeltet, for forhåbentlig at udslette nogle af de mere wingnut-poster.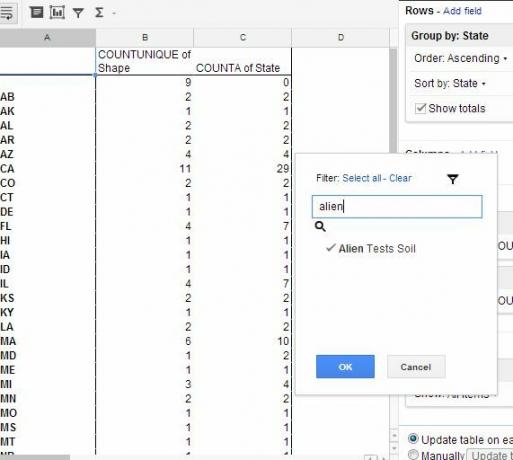
Dette afslører faktisk nogle ret interessante ting lige fra flagermus, såsom det faktum, at Californien helt klart har det højeste antal rapporterede observationer af enhver anden stat sammen med sondringen i at rapportere det største antal håndværksformer i EU Land. Det viser også, at Massachusetts, Florida og Illinois også er store møder i UFO-observationsafdelingen (i det mindste i de seneste data).
En anden sej ting ved Google Spreadsheet er det brede udvalg af diagrammer, der er tilgængelige for dig, inklusive et Geo-Map, der giver dig mulighed lægge "hot spots" af data i et grafisk format, der virkelig skiller sig ud og gør disse forbindelser inden for dataene ret indlysende.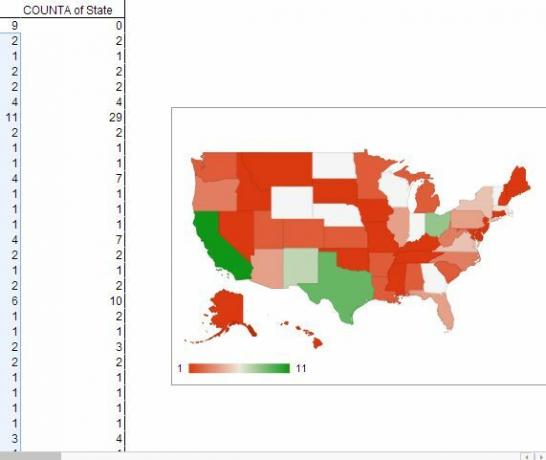
Hvis du tænker over det, er dette virkelig kun toppen af isbjerget. Hvis du nu kan importere data fra datatabeller på en hvilken som helst side på Internettet, skal du bare tænke på mulighederne. Få de seneste aktienumre eller de seneste top 10 bøger og forfattere på New York Times bestsellerliste eller verdens mest solgte biler. Der er HTML-tabeller derude om næsten ethvert emne, du kan forestille dig, og i mange tilfælde opdateres disse tabeller ofte.
ImportHtml giver dig muligheden for at tilslutte dit Google Spreadsheet til Internettet og mate de data, der findes derude. Det kan blive din egen personlige hub af information, som du kan bruge til at manipulere og massere til et format, som du faktisk kan arbejde med. Det er bare en meget mere lækker ting at elske ved Google Spreadsheet.
Har du nogensinde importeret data til dine regneark? Hvilken slags interessante ting opdagede du i disse data? Hvordan brugte du dataene? Del dine oplevelser og ideer i kommentarfeltet nedenfor!
Billedkreditter: Forretningsgrafik
Ryan har en BSc-grad i elektroteknik. Han har arbejdet 13 år inden for automatisering, 5 år inden for it, og er nu en applikationsingeniør. En tidligere administrerende redaktør for MakeUseOf, han har talt på nationale konferencer om datavisualisering og har været vist på nationalt tv og radio.