Reklame
Er du en tro på ideen om, at når der først er offentliggjort noget på Internettet, det er offentliggjort for evigt? Nå, i dag vil vi fjerne den myte.
Sandheden er, at det i mange tilfælde er meget muligt at udrydde information fra Internettet. Sikker på, der er en registrering af websider, der er blevet slettet, hvis du søger på Wayback-maskine, højre? Yup, absolut. På Wayback Machine findes der poster over websider, der går mange år tilbage - sider, som du ikke finder med en Google-søgning, fordi websiden ikke længere findes. En person slettede det, ellers blev webstedet lukket ned.
Så der er ikke noget at omgå det, ikke? Oplysninger vil for evigt blive indgraveret i stenen på Internettet, der i generationer at se? Ikke nøjagtigt.
Sandheden er, at selvom det kan være vanskeligt eller umuligt at udslette større nyhedshistorier, der er spredt fra et nyhedswebsted eller blog til et andet som en virus, det er faktisk ret let at udrydde en webside eller flere websider fra alle eksistensregister - for at fjerne denne side for både søgemaskiner såvel som det
Wayback-maskine Den nye Wayback-maskine lader dig visuelt rejse tilbage i InternettetDet ser ud til, at siden Wayback Machine-lanceringen i 2001, har ejere af webstedet besluttet at smide den Alexa-baserede back-end ud og redesigne den med deres egen open source-kode. Efter gennemførelse af test med ... Læs mere . Der er selvfølgelig en fangst, men vi kommer til det.3 måder til at fjerne blogsider fra nettet
Den første metode er den, flertallet af webstedsejere bruger, fordi de ikke ved noget bedre - blot at slette websider. Dette kan ske, fordi du er klar over, at du har duplikatindhold på dit websted, eller fordi du har en side, som du ikke ønsker at vise i søgeresultater.
Slet blot siden
Problemet med at slette sider helt fra dit websted er, at da du allerede har oprettet siden på siden netto, er der sandsynligvis links fra dit eget websted såvel som eksterne links fra andre websteder til det bestemt side. Når du sletter den, genkender Google straks den side af dig som en manglende side.
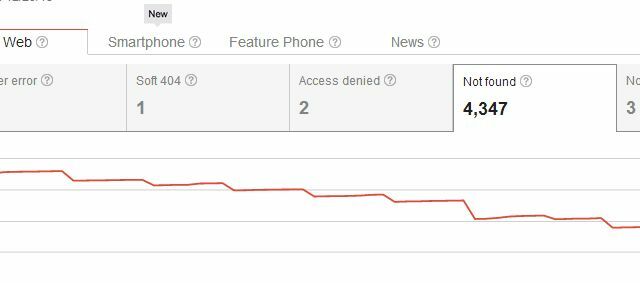
Så når du sletter din side, har du ikke kun oprettet et problem med "Ikke fundet" gennemsøgningsfejl for dig selv, men du har også oprettet et problem for alle, der nogensinde har linket til siden. Normalt vil brugere, der kommer til dit websted fra et af disse eksterne links, se din 404-side, som ikke er en stort problem, hvis du bruger noget som Googles brugerdefinerede 404-kode til at give brugerne nyttige forslag eller alternativer. Men du kunne tro, at der kunne være mere yndefulde måder at slette sider fra søgeresultaterne uden at sparke alle disse 404'er ud til eksisterende indgående links, ikke?
Nå, der er der.
Fjern en side fra Google-søgeresultater
Først og fremmest skal du forstå, at hvis den webside, du vil fjerne fra Google-søgeresultater, ikke er en side fra dit eget sted, så er du heldig, medmindre der er juridiske grunde, eller hvis webstedet har offentliggjort dine personlige oplysninger online uden din tilladelse. Hvis det er tilfældet, så brug Googles fejlfinding til fjernelse for at indsende en anmodning om at få siden fjernet fra søgeresultaterne. Hvis du har en gyldig sag, kan det være din succes at få siden fjernet - selvfølgelig har du måske endnu større succes bare kontakte webstedsejeren Sådan fjernes falske personlige oplysninger på InternettetOnline-privatliv er ikke garanteret længere. Lær hvordan du rapporterer et websted og fjerner personlige oplysninger fra internettet. Læs mere som jeg beskrev, hvordan man gør tilbage i 2009.
Nu, hvis den side, du vil fjerne fra søgeresultaterne, findes på dit eget websted, er du heldig. Alt hvad du skal gøre er at oprette en robots.txt arkiver og sørg for, at du enten ikke har tilladt den specifikke side, du ikke ønsker i søgeresultaterne, eller hele biblioteket med det indhold, du ikke ønsker, indekseres. Sådan ser blokeringen af en enkelt side ud.
Bruger-agent: * Disallow: /my-deleted-article-th-i-want-removed.html
Du kan blokere bots fra at gennemgå hele mapper på dit websted som følger.
Bruger-agent: * Disallow: / content-about-personal-stuff /
Google har en fremragende support side der kan hjælpe dig med at oprette en robots.txt-fil, hvis du aldrig har oprettet en før. Dette fungerer ekstremt godt, som jeg for nylig har forklaret i en artikel om strukturering af syndikationsaftaler Sådan forhandles syndikationsaftaler og beskytter dine søgerangeringerSyndikering er alt det vrede i disse dage. Men pludselig kunne du opdage, at syndikationspartneren er listet højere end dig i søgeresultaterne efter en historie, som du oprindeligt skrev! Beskyt dine søgerangeringer. Læs mere så de ikke skader dig (beder syndikationspartnere om at afvise indeksering af deres sider, hvor du er syndikeret). Når min egen syndikationspartner accepterede at gøre dette, forsvandt siderne, der blev duplikeret indhold fra min blog, helt fra søgelister.
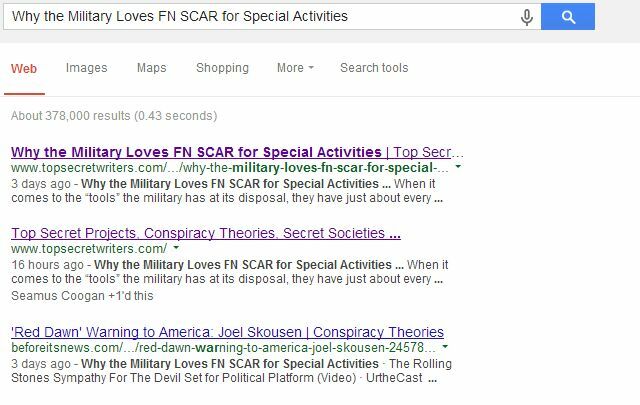
Kun hovedwebstedet kommer op på tredjepladsen for den side, hvor de viser vores titel, men min blog er nu opført på både det første og det andet sted; noget, der ville have været næsten umuligt, hvis et websted med højere autoritet havde forladt den duplikerede side indekseret.
Hvad mange mennesker ikke er klar over, er, at dette også er muligt at opnå med Internet Archive (Wayback Machine). Her er de linjer, du har brug for at føje til din robots.txt-fil for at få det til at ske.
Bruger-agent: ia_archiver. Afvis: / sample-kategori /
I dette eksempel beder jeg Internet Archive om at fjerne noget i underkatalogen til eksempler på kategori på mit websted fra Wayback Machine. Internetarkivet forklarer, hvordan man gør dette på deres Hjælpeside for ekskludering. Det er også her, de forklarer, at "Internetarkivet ikke er interesseret i at tilbyde adgang til websteder eller andre internetdokumenter, hvis forfattere ikke ønsker deres materiale i samlingen."
Dette flyver i modsætning til den almindelige opfattelse af, at alt, der sendes til Internettet, bliver fejet ind i arkivet i all evighed. Nope - webmastere, der ejer indholdet, kan specifikt få indholdet fjernet fra arkivet ved hjælp af robots.txt-metoden.
Fjern en individuel side med metatags
Hvis du kun har et par individuelle sider, som du vil fjerne fra Google-søgeresultater, behøver du faktisk ikke at bruge robots.txt-metoden overhovedet kan du blot tilføje det rigtige "robotter" metatag til de enkelte sider og fortælle robotterne om ikke at indeksere eller følge links på hele side.
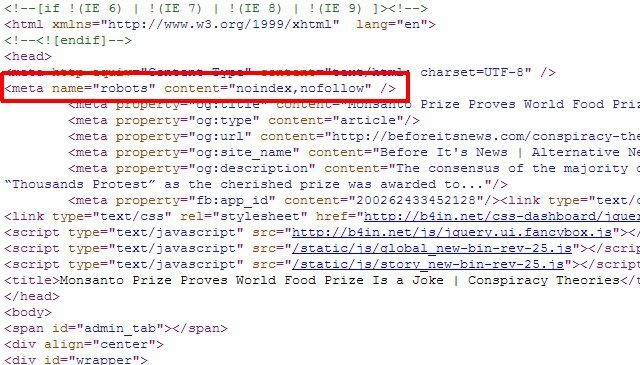
Du kan bruge metoden "robotter" ovenfor for at forhindre robotter i at indeksere siden, eller du kan specifikt fortælle det til Google-roboten ikke at indeksere, så siden kun fjernes fra Google-søgeresultater, og andre søgerobotter kan stadig få adgang til siden indhold.
Det er helt op til dig, hvordan du vil administrere, hvad robotter gør med siden, og om siden bliver listet eller ej. For bare nogle få individuelle sider kan dette være den bedre tilgang. Gå til robots.txt-metoden for at fjerne en hel mappe med indhold.
Ideen om at "fjerne" indhold
Denne slags vender hele opfattelsen af at "slette indhold fra Internettet" på hovedet. Teknisk set, hvis du fjerner alle dine egne links til en side på dit websted, og du fjerner det fra Google Søgning og Internetarkiv ved hjælp af robots.txt-teknikken, siden er til alle formål "slettet" fra Internettet. Den seje ting er dog, at hvis der er eksisterende links til siden, fungerer disse links stadig, og du udløser ikke 404 fejl for disse besøgende.
Det er en mere "blid" tilgang til at fjerne indhold fra Internettet uden helt at skjule dit websteds eksisterende link-popularitet på Internettet. I sidste ende er det op til dig, men altid, hvordan du går hen til styre det indhold, der indsamles af søgemaskiner og Internetarkivet husk, at trods hvad folk siger om levetiden for ting, der bliver sendt online, er det virkelig inden for dit styring.
Ryan har en BSc-grad i elektroteknik. Han har arbejdet 13 år inden for automatisering, 5 år inden for it, og er nu en applikationsingeniør. En tidligere administrerende redaktør for MakeUseOf, han har talt på nationale konferencer om datavisualisering og har været vist på nationalt tv og radio.


