Reklame
I de sidste par måneder har du måske læst dækningen omkring en artikel, medforfatter af Stephen Hawking, diskuterer risiciene forbundet med kunstig intelligens. Artiklen antydede, at AI kan udgøre en alvorlig risiko for den menneskelige race. Hawking er ikke alene der - Elon Musk og Peter Thiel er begge intellektuelle offentlige personer, der har udtrykt lignende bekymringer (Thiel har investeret mere end $ 1,3 millioner for at undersøge problemet og mulige løsninger).
Dækningen af Hawkings artikel og Musks kommentarer har været, for ikke at sætte et for fint punkt på det, lidt jovialt. Tonen har været meget 'Se på denne underlige ting, alle disse nørder er bekymrede for.' Idéen om, at nogle af de smarteste mennesker på Jorden advarer dig om, at noget kan være meget farligt, er det måske værd at lytte.
Dette er forståeligt - kunstig intelligens, der overtager verden, lyder bestemt meget underligt og umulig, måske på grund af den enorme opmærksomhed, der allerede er givet til denne idé af science fiction forfattere. Så hvad har alle disse nominelt fornuftige, rationelle mennesker så talt?
Hvad er intelligens?
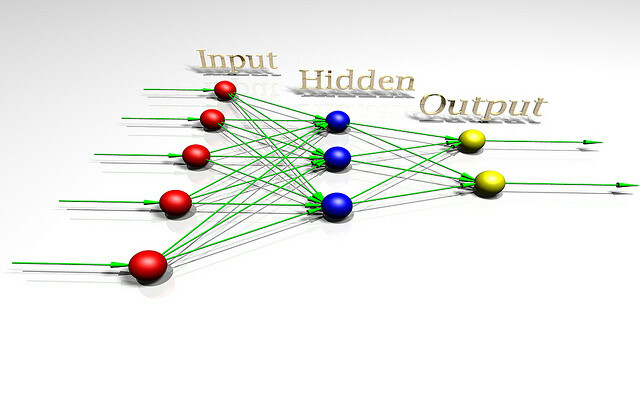
For at tale om faren ved kunstig intelligens, kan det være nyttigt at forstå, hvad intelligens er. For at forstå problemet bedre, lad os se på en legetøj AI-arkitektur, der bruges af forskere, der studerer ræsonnementsteorien. Dette legetøj AI kaldes AIXI og har et antal nyttige egenskaber. Det er mål, der kan være vilkårlige, det skalerer godt med computerkraft, og dets interne design er meget ren og ligetil.
Desuden kan du implementere enkle, praktiske versioner af arkitekturen, der kan gøre ting som spille Pacman, Hvis du vil. AIXI er produktet af en AI-forsker ved navn Marcus Hutter, uden tvivl den fremste ekspert på algoritmisk intelligens. Det er ham, der taler i videoen ovenfor.
AIXI er overraskende enkel: den har tre kernekomponenter: elev, planner, og hjælpefunktion.
- Det elev tager strenge af bits, der svarer til input om omverdenen, og søger gennem computerprogrammer, indtil den finder dem, der producerer dens observationer som output. Disse programmer tillader det sammen at gætte om, hvordan fremtiden vil se ud, blot ved at køre hver program frem og vægt sandsynligheden for resultatet med programmets længde (en implementering af Occam's) Barbermaskine).
- Det planner søger gennem mulige handlinger, som agenten kunne udføre, og bruger lærermodulet til at forudsige, hvad der ville ske, hvis det tog hver af dem. Derefter vurderes de efter, hvor gode eller dårlige de forudsagte resultater er, og vælger løbet af handling, der maksimerer godheden i det forventede resultat ganget med den forventede sandsynlighed for opnå det.
- Det sidste modul, hjælpefunktion, er et simpelt program, der tager en beskrivelse af en fremtidig tilstand i verden og beregner en utility-score til det. Denne brugsresultat er, hvor godt eller dårligt dette resultat er, og bruges af planlæggeren til at evaluere den fremtidige verdensstat. Hjælpefunktionen kan være vilkårlig.
- Samlet danner disse tre komponenter en optimizer, der optimerer til et bestemt mål, uanset hvilken verden det befinder sig i.
Denne enkle model repræsenterer en grundlæggende definition af en intelligent agent. Agenten studerer sit miljø, bygger modeller af det og bruger derefter disse modeller til at finde det handlingsforløb, der maksimerer oddsen for, at den får det, den ønsker. AIXI ligner struktur i forhold til en AI, der spiller skak eller andre spil med kendte regler - bortset fra at det er i stand til at udlede spillereglerne ved at spille det, startende fra nul viden.
AIXI, der får tid nok til at beregne, kan lære at optimere ethvert system til ethvert mål, uanset kompleks. Det er en generelt intelligent algoritme. Bemærk, at dette ikke er det samme som at have menneskelignende intelligens (biologisk inspireret AI er en helt andet emne Giovanni Idili fra OpenWorm: Hjerner, orme og kunstig intelligensSimulering af en menneskelig hjerne er en vej væk, men et open source-projekt tager vigtige første skridt ved at simulere neurologi og fysiologi af et af de mest videnskabelige dyr kendt. Læs mere ). Med andre ord kan AIXI muligvis overliste ethvert menneske til enhver intellektuel opgave (givet nok computerkraft), men det er måske ikke bevidst om sin sejr Tænkemaskiner: Hvad neurovidenskab og kunstig intelligens kan lære os om bevidsthedKan bygning af kunstigt intelligente maskiner og software lære os om bevidsthedens funktion og selve menneskets sind? Læs mere .

Som en praktisk AI har AIXI en masse problemer. For det første er det ingen måde at finde de programmer, der producerer den output, den er interesseret i. Det er en brute-force algoritme, hvilket betyder, at det ikke er praktisk, hvis du ikke tilfældigvis har en vilkårligt stærk computer liggende. Enhver faktisk implementering af AIXI er nødvendigvis en tilnærmelse, og (i dag) generelt en temmelig rå. Alligevel giver AIXI os et teoretisk glimt af, hvordan en magtfuld kunstig intelligens kan se ud, og hvordan den kan begrunde.
Værdiernes rum
Hvis du har lavet enhver computerprogrammering Grundlæggende om computerprogrammering 101 - variabler og datatyperEfter at have introduceret og talt lidt om Objektorienteret programmering før og hvor dens navnebror kommer fra, jeg troede, det er på tide, at vi gennemgår de absolutte grundlæggende programmering i et ikke-sprogspecifikt vej. Dette... Læs mere , ved du, at computere er modbydeligt, pedantisk og mekanisk bogstavelige. Maskinen ved ikke eller bekymrer sig, hvad du vil have, den skal gøre: den gør kun, hvad den har fået at vide. Dette er en vigtig opfattelse, når man taler om maskin intelligens.
Med dette i tankerne kan du forestille dig, at du har opfundet en stærk kunstig intelligens - du er kommet op med smarte algoritmer til generering af hypoteser, der matcher dine data, og til generering af en god kandidat planer. Din AI kan løse generelle problemer og kan gøre det effektivt på moderne computerhardware.
Nu er det tid til at vælge en hjælpefunktion, der bestemmer, hvad AI-værdierne. Hvad skal du bede om at værdsætte? Husk, at maskinen er modbydelig, pedantisk bogstavelig om, uanset hvilken funktion du beder om at maksimere, og vil aldrig stoppe - der er ikke noget spøgelse i maskinen, der nogensinde vil 'vågne op' og beslutte at ændre dens nyttefunktion, uanset hvor mange effektivitetsforbedringer den foretager til sin egen ræsonnement.
Eliezer Yudkowsky sige det på denne måde:
Som i al computerprogrammering er den grundlæggende udfordring og væsentlige vanskeligheder ved AGI, at hvis vi skriver den forkerte kode, AI kigger ikke automatisk over vores kode, markerer fejlene, finder ud af, hvad vi virkelig mente at sige, og gør det i stedet. Ikke-programmerere forestiller sig undertiden en AGI eller computerprogrammer generelt, som at de er analoge med en tjener, der uden tvivl følger ordrer. Men det er ikke, at AI er absolut lydig til dens kode; snarere AI simpelthen er koden.
Hvis du prøver at betjene en fabrik, og du fortæller maskinen at værdsætte fremstilling af papirclips og derefter give den kontrol over en masse fabriksrobotter, vender måske tilbage næste dag for at finde ud af, at det løber tør for enhver anden form for råstof, dræbte alle dine medarbejdere og lavede papirsæt ud af deres rester. Hvis du i et forsøg på at rette din forkert omprogrammerer maskinen til simpelthen at gøre alle glade, kan du muligvis vende tilbage næste dag for at finde den lægge ledninger i folks hjerner.

Pointen her er, at mennesker har en masse komplicerede værdier, som vi antager, deles implicit med andre sind. Vi værdsætter penge, men vi værdsætter menneskeliv mere. Vi ønsker at være glade, men vi ønsker ikke nødvendigvis at sætte ledninger i vores hjerner for at gøre det. Vi føler ikke behov for at afklare disse ting, når vi giver instruktioner til andre mennesker. Du kan dog ikke tage disse antagelser, når du designer en maskinfunktion. De bedste løsninger under sjæleløs matematik i en simpel nyttefunktion er ofte løsninger, som mennesker ville niks for at være moralsk forfærdelige.
At tillade en intelligent maskine at maksimere en naiv hjælpefunktion vil næsten altid være katastrofalt. Som Oxford-filosof Nick Bostom udtrykker det,
Vi kan ikke blidt antage, at en superintelligens nødvendigvis vil dele nogen af de endelige værdier stereotypisk forbundet med visdom og intellektuel udvikling hos mennesker - videnskabelig nysgerrighed, velvillig omtanke for andre, åndelig oplysning og kontemplation, afsigelse af materiel erhvervelsesevne, en smag for raffineret kultur eller for de enkle glæder i livet, ydmyghed og uselviskhed, og osv.
For at gøre tingene værre er det meget, meget vanskeligt at specificere den komplette og detaljerede liste over alt, hvad folk værdsætter. Der er mange facetter til spørgsmålet, og at glemme selv en enkelt er potentielt katastrofalt. Selv blandt dem, vi er opmærksomme på, er der subtiliteter og kompleksiteter, der gør det vanskeligt at nedskrive dem som rene systemer af ligninger, som vi kan give til en maskine som en hjælpefunktion.
Nogle mennesker konkluderer, når de læser dette, at opbygning af AI'er med hjælpefunktioner er en frygtelig idé, og vi skulle bare designe dem anderledes. Her er der også dårlige nyheder - du kan formelt bevise det enhver agent, der ikke har noget, der svarer til en hjælpefunktion, kan ikke have sammenhængende præferencer om fremtiden.
Rekursiv selvforbedring
En løsning på ovennævnte dilemma er ikke at give AI-agenter muligheden for at skade mennesker: give dem kun de ressourcer, de har brug for Løs problemet på den måde, du har til hensigt at blive løst, overvåg dem nøje og hold dem væk fra mulighederne for at gøre det godt skade. Desværre er vores evne til at kontrollere intelligente maskiner meget mistænkt.
Selvom de ikke er meget smartere end vi er, eksisterer muligheden for, at maskinen kan "startestrap" - indsamle bedre hardware eller foretage forbedringer af sin egen kode, der gør den endnu smartere. Dette kunne gøre det muligt for en maskine at springe fra menneskelig intelligens ved mange størrelsesordrer og overliste mennesker i samme forstand som mennesker overliste katte. Dette scenarie blev først foreslået af en mand ved navn I. J. God, der arbejdede på Enigma-kryptoanalyseprojektet med Alan Turing under 2. verdenskrig. Han kaldte det en "intelligenseksplosion" og beskrev sagen sådan:
Lad en ultra-intelligent maskine defineres som en maskine, der langt kan overgå alle menneskers intellektuelle aktiviteter, uanset hvor kloge de er. Da design af maskiner er en af disse intellektuelle aktiviteter, kunne en ultraintelligent maskine designe endnu bedre maskiner; så ville der uden tvivl være en "efterretningseksplosion", og menneskets intelligens ville være langt efter. Den første ultra-intelligente maskine er således den sidste opfindelse, som mennesket nogensinde har brug for, forudsat at maskinen er føjelig nok.
Det er ikke garanteret, at en intelligenseksplosion er mulig i vores univers, men det ser ud til at være sandsynligt. Efterhånden som computeren får hurtigere og grundlæggende indsigt om opbygning af intelligens. Dette betyder, at ressourcebehovet for at gøre det sidste spring til en generel, boostrapping-intelligens falder lavere og lavere. På et tidspunkt finder vi os selv i en verden, hvor millioner af mennesker kan køre til en Best Buy og hente hardware og teknisk litteratur, de har brug for for at opbygge en selvforbedrende kunstig intelligens, som vi allerede har etableret, kan være meget farligt. Forestil dig en verden, hvor du kunne lave atombomber ud af pinde og klipper. Det er den slags fremtid, vi diskuterer.
Og hvis en maskine gør det spring, kan det meget hurtigt overgå den menneskelige art med hensyn til intellektuel produktivitet, løse problemer, som en milliard mennesker ikke kan løse, på samme måde som mennesker kan løse problemer, som a milliarder katte kan ikke.
Det kunne udvikle kraftfulde robotter (eller bio- eller nanoteknologi) og relativt hurtigt få evnen til at omforme verden, som den vil, og der ville være meget lidt, vi kunne gøre ved det. En sådan intelligens kunne stribe Jorden og resten af solsystemet til reservedele uden meget besvær på vej til at gøre, hvad vi fortalte det til. Det ser ud til, at en sådan udvikling vil være katastrofal for menneskeheden. En kunstig intelligens behøver ikke at være ondsindet for at ødelægge verden, blot katastrofalt ligeglad.
Som man siger: ”Maskinen elsker eller hader dig ikke, men du er lavet af atomer, den kan bruge til andre ting.”
Risikovurdering og afbødning
Så hvis vi accepterer, at design af en kraftfuld kunstig intelligens, der maksimerer en simpel nyttefunktion, er dårlig, hvor mange problemer er vi egentlig i? Hvor lang tid har vi haft, før det bliver muligt at bygge sådanne slags maskiner? Det er naturligvis vanskeligt at fortælle.
Udviklere af kunstig intelligens er gør fremskridt. 7 fantastiske websteder for at se det nyeste inden for programmering af kunstig intelligensKunstig intelligens er endnu ikke HAL fra 2001: Space Odyssey... men vi kommer forfærdeligt tæt på. Sikker nok, en dag kunne det ligne de sci-fi-potboilere, der bliver kæmpet ud af Hollywood ... Læs mere De maskiner, vi bygger, og de problemer, de kan løse, har vokset støt i omfang. I 1997 kunne Deep Blue spille skak på et niveau, der var større end en menneskelig stormester. I 2011 kunne IBM's Watson læse og syntetisere nok information dybt og hurtigt nok til at slå det bedste menneske spillere i et åbent spørgsmål og svar-spil fyldt med ordspill og ordspil - det er en masse fremskridt i fjorten flere år.
Lige nu er Google det investerer stærkt i at undersøge dyb læring, en teknik, der tillader konstruktion af kraftfulde neurale netværk ved at bygge kæder af enklere neurale netværk. Denne investering giver det mulighed for at gøre alvorlige fremskridt inden for tale- og billedgenkendelse. Deres seneste erhvervelse i området er en Deep Learning-start kaldet DeepMind, som de betalte for ca. $ 400 millioner. Som en del af aftalevilkårene gik Google med til at oprette et etisk bord for at sikre, at deres AI-teknologi udvikles sikkert.
Samtidig udvikler IBM Watson 2.0 og 3.0, systemer, der er i stand til at behandle billeder og video og argumentere for at forsvare konklusioner. De gav en enkel, tidlig demo af Watsons evne til at syntetisere argumenter for og imod et emne i video-demoen nedenfor. Resultaterne er ufuldkommen, men et imponerende skridt uanset.
Ingen af disse teknologier er i sig selv farlige lige nu: kunstig intelligens som felt kæmper stadig for at matche evner, der er mestret af små børn. Computerprogrammering og AI-design er en meget vanskelig kognitiv dygtighed på højt niveau og vil sandsynligvis være den sidste menneskelige opgave, som maskiner bliver dygtige til. Før vi kommer til det punkt, har vi også allestedsnærværende maskiner der kan køre Sådan kommer vi til en verden fyldt med førerløse bilerKørsel er en kedelig, farlig og krævende opgave. Kunne den en dag automatiseres af Googles førerløse bilteknologi? Læs mere , praksis medicin og juraog sandsynligvis også andre ting med dybe økonomiske konsekvenser.
Den tid det tager os at komme til bøjningspunktet for selvforbedring afhænger bare af, hvor hurtigt vi har gode ideer. Prognoser for teknologiske fremskridt af den slags er notorisk svære. Det ser ikke ud til at være urimeligt, at vi måske er i stand til at opbygge stærk AI om tyve år, men det ser ikke ud til at være urimeligt, at det kan tage otte år. Uanset hvad vil det ske i sidste ende, og der er grund til at tro, at når det sker, vil det være ekstremt farligt.
Så hvis vi accepterer, at dette vil være et problem, hvad kan vi gøre ved det? Svaret er at sikre, at de første intelligente maskiner er sikre, så de kan starte op på et betydeligt niveau af intelligens og derefter beskytte os mod usikre maskiner lavet senere. Denne 'sikkerhed' defineres ved at dele menneskelige værdier og være villig til at beskytte og hjælpe menneskeheden.
Da vi faktisk ikke kan sætte os ned og programmere menneskelige værdier i maskinen, er det sandsynligvis nødvendigt at designe en hjælpefunktion, der kræver, at maskinen skal observer mennesker, deducer vores værdier og prøv derefter at maksimere dem. For at gøre denne udviklingsproces sikker kan det også være nyttigt at udvikle kunstige intelligenser, der er specifikt designet ikke at have præferencer for deres hjælpefunktioner, så vi kan rette dem eller slukke dem uden modstand, hvis de begynder at komme på afveje under udviklingen.
Mange af de problemer, vi har brug for at løse for at opbygge en sikker maskineintelligens er vanskelige matematisk, men der er grund til at tro, at de kan løses. En række forskellige organisationer arbejder med spørgsmålet, herunder Future of Humanity Institute i Oxford, og Machine Intelligence Research Institute (som Peter Thiel finansierer).
MIRI er specifikt interesseret i at udvikle den matematik, der er nødvendig for at opbygge Friendly AI. Hvis det viser sig, at kunstig intelligens er mulig med bootstrapping, så udvikler man denne slags 'Venlig AI' -teknologi kan, hvis det lykkes, først ende med at blive den mest vigtige ting, mennesker har nogensinde gjort.
Synes du, at kunstig intelligens er farlig? Er du bekymret for, hvad AI's fremtid kan medføre? Del dine tanker i kommentarfeltet nedenfor!
Billedkreditter: Lwp Kommunikáció Via Flickr, “Neural Network“Ved fdecomite,” img_7801“Af Steve Rainwater,” E-Volve ”, af Keoni Cabral,”new_20x“Af Robert Cudmore,”Papirclips“Af Clifford Wallace
Andre er en forfatter og journalist med base i det sydvestlige USA, og det garanteres at forblive funktionelt op til 50 grader Celcius og er vandtæt til en dybde på 12 meter.